High Quality Entity Segmentation

In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provides more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of 1.9 on the challenging fine-grained entity segmentation task. The dataset and code will be released.
The EntitySeg dataset contains 33,227 images with high-quality mask annotations. Compared with existing dataets, there are three distinct properties in EntitySeg. First, 71.25% and 86.23% of the images are of high resolution with at least 2000px for the width and 1000px for the height which is more consistent with current digital imaging trends. Second, our dataset is open-world and is not limited to predefined classes. We regard every semantically-coherent region in the images as an entity, even if it is a blurred region or it cannot be semantically recognized easily. Third, the mask annotation along the boundaries are more accurate than existing datasets, as shown in above figure. Our dataset is still growing and will be enlarged to about 42,000 images.
The following figure shows some statistics information of Entity dataset. The sub-figures (a) and (b) illustrate the distribution comparison of image resolution and average entity numbers comparison among ADE20K, COCO, and our EntitySeg. The sub-figure (c) indicates the distribution of image sources we collected from.
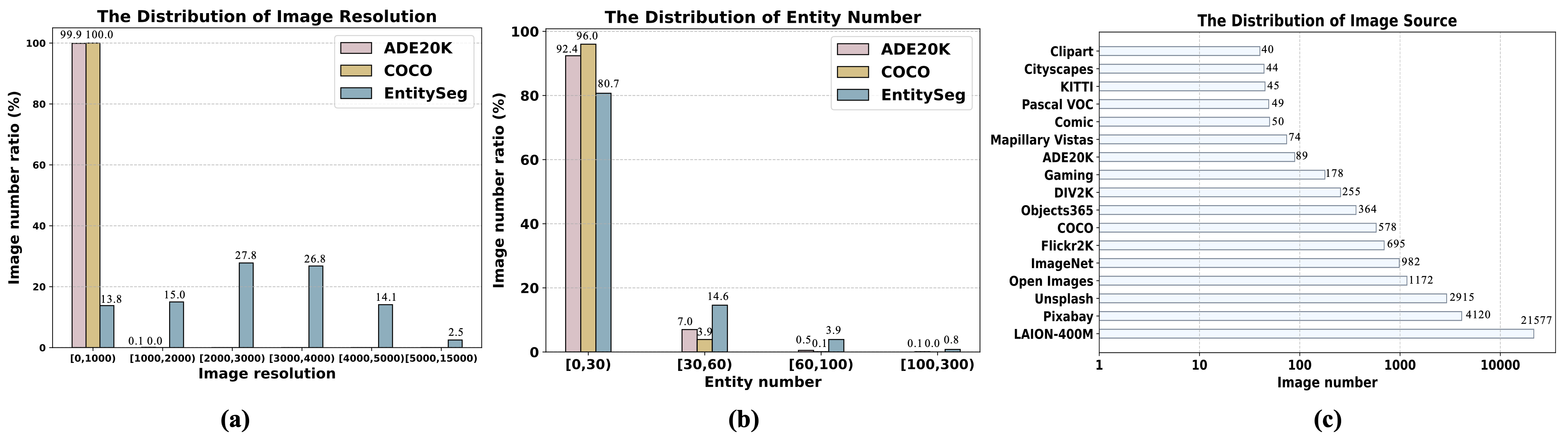
In the following, we show the statistics comparison among COCO, ADE20K and our EntitySeg. The `ImageRes (avg)', `EntityNum (avg)', `Valid Area', `Entity Complexity', and `Entity Simplicity' indicate the average value of image resolution size, entity numbers per image, valid area ratio per image, average entity complexity and simplicity respectively. The `EntityNum (max)' means the max entity numbers per image.

We evaluate widely-used segmentation models on our fine-grained segmentation dataset. The high-resolution images and ground-truth (GT) masks in our dataset bring new challenges to existing segmentation approaches. The segmentation quality is sacrificed if we downsample the images and GT masks to 800px resolution during training (standard practice in Detectron2 or MMDetection), whereas using a larger input resolution causes out of memory issues on GPUs.
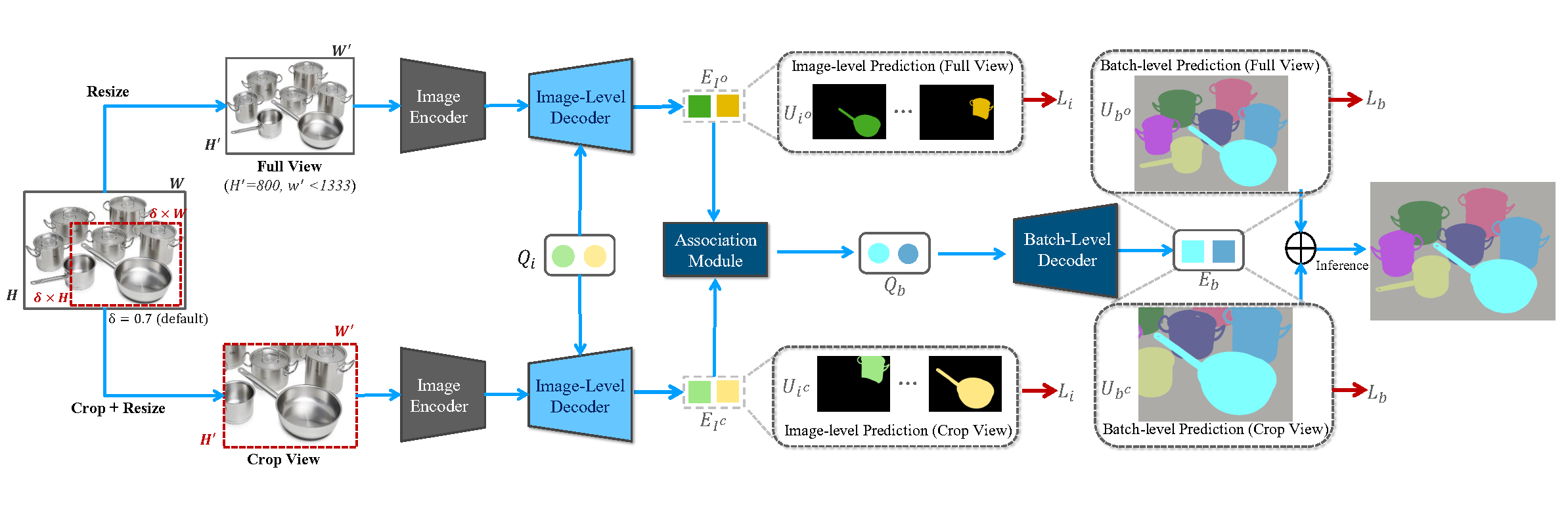
We propose CropFormer to tackle the high-resolution segmentation problem using a divide-and-conquer approach. CropFormer generates mask predictions from both the full image and its high-resolution crops, and then ensemble their mask predictions. During training, we randomly select one of the predefined 4 corner crops to pair with the full image. During inference, we apply Cropformer to all corner crops to ensemble their mask prediction results. The key strength of CropFormer is to utilize the same queries to associate the same entities across the full image and its crops, allowing us t o ensemble their mask predictions during inference to obtain stronger final results. Our work is the first to overcome the limitation of existing query-based segmentation methods being not compatible with test-time augmentation (TTA), due to unassociated queries across different image views.


We use the CropFormer wrapped with swin-large backbone to infer the test set of EntitySeg Dataset. The sub-figures shows the image input, the inference results of full image, four crops or both of them, and ground truth from left to right.



@inproceedings{qilu2023high,
title={High-Quality Entity Segmentation},
author={Lu, Qi and Jason Kuen and Tiancheng, Shen and Jiuxiang, Gu and Weidong, Guo and Jiaya, Jia and Zhe, Lin and Ming-Hsuan, Yang},
booktitle={ICCV},
year={2023}
}
Acknowledgements: The EntitySeg Dataset is funded by Adobe Inc. For the website, we use the template of the DreamBooth. Thanks for their beautiful web design.